

Bevy 0.12
于 2023 年 11 月 4 日由 Bevy 贡献者发布

感谢 **185** 位贡献者、**567** 个拉取请求、社区审阅者以及我们慷慨的赞助商,我们很高兴宣布 **Bevy 0.12** 版本已在 crates.io 上发布!
对于那些不知道的人来说,Bevy 是一个用 Rust 构建的令人耳目一新的简单数据驱动游戏引擎。您可以查看我们的 快速入门指南,立即尝试一下。它是免费的,并且永远开源!您可以在 GitHub 上获取完整的 源代码。查看 Bevy Assets,获取由社区开发的插件、游戏和学习资源的集合。
要将现有 Bevy 应用或插件更新到 **Bevy 0.12**,请查看我们的 0.11 到 0.12 迁移指南。
自从我们几个月前的上一个版本以来,我们添加了大量的功能、错误修复和质量改进,但以下是一些亮点。
- **延迟渲染**:(可选)支持以延迟方式渲染,它通过添加对新效果和不同性能权衡的支持来补充 Bevy 现有的 Forward+ 渲染器。Bevy 现在是一个“混合”渲染器,这意味着您可以同时使用两者!
- **Bevy Asset V2**:一个全新的资产系统,它添加了对资产预处理、资产配置(通过 .meta 文件)、多个资产源、递归依赖项加载跟踪等的 支持!
- **PCF 阴影过滤**:由于使用了百分比更近过滤,Bevy 现在拥有更平滑的阴影。
- **StandardMaterial 光线透射**:Bevy 的 PBR 材质现在支持光线透射,使模拟玻璃、水、塑料、树叶、纸张、蜡、大理石等材料成为可能。
- **材质扩展**:材质现在可以构建在其他材质之上。您现在可以轻松编写基于现有材质(例如 Bevy 的 PBR StandardMaterial)的着色器。
- **Rusty 着色器导入**:Bevy 的细粒度着色器导入系统现在使用 Rust 风格的导入,扩展了导入系统的功能和可用性。
- **Android 上的暂停和恢复**:Bevy 现在支持 Android 上的暂停和恢复事件,这是我们 Android 故事中最后一块缺失的拼图。Bevy 现在支持 Android!
- **绘制命令的自动批处理和实例化**:绘制命令现在会在可能的情况下自动进行批处理/实例化,从而带来显著的渲染性能提升。
- **渲染器优化**:Bevy 的渲染器数据流已经过重新设计,以挤出更多性能并为未来的 GPU 驱动渲染做好准备。
- **一次性系统**:ECS 系统现在可以按需从其他系统运行!
- **UI 材质**:将自定义材质着色器添加到 Bevy UI 节点。
延迟渲染 #
两种最流行的“渲染风格”是
- **正向渲染**:在一个渲染通道中完成所有材质/光照计算
- **优点**:更易于使用。在更多硬件上运行/性能更好。支持 MSAA。很好地处理透明度。
- **缺点**:光照更昂贵/场景中支持的光照更少,一些渲染效果在没有预处理的情况下是不可能的(或更难实现)。
- **延迟渲染**:进行一个或多个预处理通道以收集有关场景的相关信息,然后在这些信息之后,在最终通道中屏幕空间中进行材质/光照计算。
- **优点**:启用正向渲染中不可能实现的一些渲染效果。这对于 GI 技术尤其重要,通过仅对可见片段进行着色来降低着色成本,可以在场景中支持更多光源
- **缺点**:更复杂。需要进行预处理,这在某些情况下可能比等效的正向渲染器更昂贵(尽管反过来也可能是真的),使用更多纹理带宽(这在某些设备上可能很昂贵),不支持 MSAA,透明度更难/不太直接。
历史上,Bevy 的渲染器一直是“正向渲染器”。更准确地说,它是一个 聚类正向/Forward+ 渲染器,这意味着我们将视锥体划分为簇,并将光源分配到这些簇,使我们能够渲染比传统正向渲染器更多的光源。
然而,随着 Bevy 的发展,它逐渐转变为“混合渲染器”领域。在之前的版本中,我们添加了 深度和法线预处理 来启用 TAA、SSAO 以及 Alpha Texture Shadow Maps。我们还添加了一个运动向量预处理来启用 TAA。
在 **Bevy 0.12** 中,我们添加了对延迟渲染的可选支持(建立在现有的预处理工作之上)。每种材质可以选择是否要通过正向或延迟路径,并且可以在每个材质实例中配置。Bevy 还具有一个新的 DefaultOpaqueRendererMethod 资源,它配置全局默认值。默认情况下,此选项设置为“forward”。全局默认值可以按材质进行覆盖。
让我们分解这个延迟渲染的组件

当为 PBR StandardMaterial 启用延迟时,延迟预处理将 PBR 信息打包到 Gbuffer 中,可以将其分解为
**基础颜色** 
**深度** 
**法线** 
**感知粗糙度** 
**金属度** 
延迟预处理还会生成一个“延迟光照通道 ID”纹理,该纹理决定了为片段运行哪个光照着色器

这些都被传递到最终的延迟光照着色器中。
请注意,飞行头盔模型前面的立方体和地面使用正向渲染,这就是为什么它们在上面两个延迟光照纹理中都是黑色的。这说明您可以在同一个场景中使用正向和延迟材质!
请注意,对于大多数用例,我们建议默认使用正向,除非某个功能明确需要延迟,或者您的渲染条件有利于延迟样式。正向最不容易出错,并且将在更多设备上运行得更好。
PCF 阴影过滤 #
阴影混叠是 3D 应用中非常常见的问题

阴影中的“锯齿线”是阴影贴图“太小”而无法从这个角度准确地表示阴影的结果。上面的阴影贴图存储在一个 512x512 纹理中,它的分辨率低于大多数人会为其大多数阴影使用。这是为了显示“不良”的锯齿情况而选择的。请注意,Bevy 默认使用 2048x2048 阴影贴图。
一种“解决方案”是提高分辨率。以下是使用 4096x4096 阴影贴图的效果。

看起来好多了!但是,这仍然不是一个完美的解决方案。大型阴影贴图并非所有硬件都能承受。它们要贵得多。即使您可以承受超高分辨率的阴影,如果您将物体放在错误的位置或将光源指向错误的方向,仍然会遇到这个问题。您可以使用 Bevy 的 级联阴影贴图(默认情况下已启用)来覆盖更大的区域,在靠近摄像头的区域具有更高的细节,在更远的地方具有更低的细节。但是,即使在这些条件下,您仍然可能会遇到这些混叠问题。
Bevy 0.12 引入了 PCF 阴影过滤(Percentage-Closer Filtering),这是一种流行的技术,它从阴影贴图中获取多个样本,并与插值后的网格表面深度投影到光照的参考系中进行比较。然后,它计算深度缓冲区中比网格表面更靠近光的样本的百分比。简而言之,这会创建一个“模糊”效果,从而提高阴影质量,特别是在给定阴影没有足够的“阴影贴图细节”时。请注意,PCF 目前仅支持 DirectionalLight 和 SpotLight。
Bevy 0.12 的默认 PCF 方法是 ShadowMapFilter::Castano13 方法,由 Ignacio Castaño(在 The Witness 中使用)创建。以下是使用 512x512 阴影贴图的效果:
拖动此图像进行比较


好多了!
我们还实现了 ShadowMapFilter::Jimenez14 方法,由 Jorge Jimenez(在 Call of Duty Advanced Warfare 中使用)创建。它可能比 Castano 方法稍微便宜,但可能会出现闪烁。它受益于 时间抗锯齿 (TAA),这可以减少闪烁。与 Castano 相比,它也可以更平滑地混合阴影级联。
拖动此图像进行比较

StandardMaterial 光照透射 #
现在,StandardMaterial 支持许多与光照透射相关的属性
specular_transmissiondiffuse_transmissionthicknessiorattenuation_colorattenuation_distance
这些属性允许您更逼真地表示各种物理材料,包括 透明和磨砂玻璃、水、塑料、树叶、纸张、蜡、大理石、瓷器等等。
漫射透射是 PBR 照明模型中一种廉价的补充,而镜面透射是一种资源密集型屏幕空间效果,可以准确地模拟折射和模糊效果。

为了补充新的透射属性,引入了一个新的 TransmittedShadowReceiver 组件,可以将其添加到具有漫射透射材质的实体,以接收从网格另一侧投射的阴影。这对渲染像树叶或纸张这样薄的双面半透明物体最为有用。
此外,在 Camera3d 组件中添加了两个额外的字段:screen_space_specular_transmission_quality 和 screen_space_specular_transmission_steps。它们用于控制屏幕空间镜面透射效果的质量(抽头数量)以及在多个透射物体彼此叠加时支持多少“透明度层”。
重要提示:每个额外的“透明度层”都会在幕后进行纹理复制,从而增加带宽成本,因此建议将此值保持在尽可能低的水平。
最后,添加了对以下 glTF 扩展的导入器支持
KHR_materials_transmissionKHR_materials_iorKHR_materials_volume
观看此视频 以查看实际效果!
兼容性 #
镜面透射和漫射透射都与所有支持的平台兼容,包括移动设备和 Web。
可选的 pbr_transmission_textures Cargo 特性允许使用纹理来调节 specular_transmission、diffuse_transmission 和 thickness 属性。默认情况下它处于禁用状态,以减少标准材质使用的纹理绑定数量。(这些纹理绑定在低端平台和旧版 GPU 上受到严格限制!)
DepthPrepass 和 TAA 可以极大地提高屏幕空间镜面透射效果的质量,建议在支持它们的平台上与之一起使用。
实现细节 #
镜面透射是通过新的 Transmissive3d 屏幕空间折射阶段实现的,该阶段加入了现有的 Opaque3d、AlphaMask3d 和 Transparent3d 阶段。在此阶段,会拍摄主纹理的一个或多个快照,这些快照用作折射效果的“背景”。
每个片段的表面法线和 IOR(折射率)与视点方向一起使用,以计算折射光线。(通过斯涅尔定律。)然后,该光线通过网格的体积传播(由 thickness 属性控制的距离),产生一个出射点。然后,在该点对“背景”纹理进行采样。感知粗糙度与交错梯度噪声和多个螺旋抽头一起使用,以产生模糊效果。
漫射透射是通过第二个反转和位移的完全漫射朗伯叶实现的,该叶片被添加到现有的 PBR 照明计算中。这是一种简单且相对便宜的近似方法,但效果相当好。
Bevy 资产 V2 #
资产管道是游戏开发流程的核心部分。Bevy 的旧资产系统适合某些类型的应用程序,但它也存在一些限制,无法满足其他类型的应用程序(尤其是高端 3D 应用程序)的需求。
Bevy 资产 V2 是一个全新的资产系统,它汲取了 Bevy 资产 V1 最佳部分的经验,同时添加了对许多重要场景的支持:资产导入/预处理、资产元数据文件、多个资产来源、递归资产依赖加载事件、异步资产 I/O、更快且功能更丰富的资产句柄等等!
大多数现有的面向用户的资产代码要么根本不需要更改,要么只需进行少量更改。自定义 AssetLoader 或 AssetReader 代码需要稍作修改,但通常这些修改都非常小。Bevy 资产 V2(尽管是一个全新的实现)主要只是扩展了 Bevy 的能力。
资产预处理 #
资产预处理是指能够获取给定类型的输入资产,对其进行某种处理(通常在开发期间),然后使用结果作为应用程序中的最终资产。可以将其视为“资产编译器”。
这支持许多场景
- 减少发布应用程序中的工作量:许多资产并未以最适合发布的形式组成。场景可能以人类可读的文本格式定义,这会降低加载速度。图像可能以需要更多工作来解码和上传到 GPU 的格式定义,或者与 GPU 友好格式相比(例如 PNG 图像与 Basis Universal),图像在 GPU 上占用更多空间。预处理使开发人员能够提前将资产转换为发布最佳格式,从而使应用程序启动速度更快、占用更少的资源以及性能更好。它还可以将将在运行时执行的计算工作转移到开发时间。例如,为图像生成 mipmap。
- 压缩:最大程度地减少部署应用程序中资产占用的磁盘空间和/或带宽
- 转换:某些“资产源文件”默认情况下并非处于正确的格式。您可以拥有类型为
A的资产,并将其转换为类型B的资产。
如果您正在构建一款使用最佳格式测试硬件极限的应用程序...或者您只是想减少启动/加载时间,那么资产预处理非常适合您。
要深入了解我们选择的实现的详细技术分析,请查看 Bevy 资产 V2 拉取请求。
启用预处理 #
要启用资产预处理,只需像这样配置 AssetPlugin
app.add_plugins
这将配置资产系统,以便在 imported_assets 文件夹而不是 assets “源文件夹”中查找资产。在开发期间,启用 asset_processor cargo 特性标志,方法如下
这将启动 AssetProcessor,与您的应用程序并行运行。它将一直运行,直到从其源(默认为 assets 文件夹)读取所有资产、对其进行处理并将结果写入其目标(默认为 imported_assets 文件夹)为止。这与资产热重载配对。如果您进行更改,AssetProcessor 将检测到此更改,资产将被重新处理,结果将被热重载到您的应用程序中。
您今天应该启用预处理吗? #
在未来的 Bevy 版本中,我们将建议为大多数应用程序启用处理。由于以下几个原因,我们尚未建议将其用于大多数用例
- 我们大多数内置资产尚未为其实现处理器。
CompressedImageSaver是唯一的内置处理器,它具有最基本的功能集。 - 我们尚未实现“资产迁移”。每当资产更改其设置格式(在元数据文件中使用)时,我们需要能够自动将现有资产元数据文件迁移到新版本。
- 随着人们采用处理,我们预计会有一些波动,因为我们将根据反馈进行调整。
增量式和依赖关系感知 #
Bevy 资产 V2 仅处理已更改的资产。为了实现这一点,它会计算并存储每个资产源文件的哈希值
hash: ,
它还会跟踪处理资产时使用的资产依赖项。如果依赖项已更改,则依赖资产也将被重新处理!
事务性和可靠性 #
Bevy 资产 V2 使用预写式日志记录(数据库中常用的技术)从崩溃/强制退出中恢复。只要有可能,它就会避免完全重新处理,而只重新处理未完成的事务。
AssetProcessor 可以随时关闭(无论是故意还是非故意),它会从中断的地方继续处理!
如果 Bevy 应用程序请求加载当前正在处理(或重新处理)的资产,则加载将异步等待,直到已处理的资产及其元数据文件都已写入。这确保了对于给定的加载操作,加载的资产文件和元数据文件始终“匹配”。
资产元数据文件 #
资产现在支持(可选的).meta 文件。这支持配置以下内容
- 资产“操作”
- 这将配置 Bevy 的资产系统如何处理资产
Load:加载资产,不进行处理Process:在加载之前预处理资产Ignore:不处理或加载资产
- 这将配置 Bevy 的资产系统如何处理资产
AssetLoader设置- 您可以使用元数据文件设置所需的任何
AssetLoader - 配置加载器设置,例如“如何过滤图像”、“调整 3D 场景中的向上轴”等等
- 您可以使用元数据文件设置所需的任何
Process设置(如果使用Process操作)- 您可以使用元文件来设置任何您想要的
Process实现 - 配置处理器设置,例如“使用哪种压缩类型”、“是否生成 mipmaps”等
- 您可以使用元文件来设置任何您想要的
未处理图像的元文件如下所示
配置为处理的图像的元文件如下所示
如果启用了资产处理器,则将为资产自动生成元文件。
处理后的图像的最终“输出”元数据如下所示
这是写入 imported_assets 文件夹的内容。
请注意,Process 资产模式已更改为 Load。这是因为在发布的应用程序中,我们将像任何其他图像资产一样“正常”加载最终处理的图像。请注意,在这种情况下,输入和输出资产都使用 ImageLoader。但是,如果上下文要求,处理后的资产可以使用不同的加载程序。还要注意添加了 processed_info 元数据,该元数据用于确定是否需要重新处理资产。
最终的处理后的资产和元数据文件可以像任何其他文件一样查看和交互。但是,它们旨在只读。配置应该在源资产上进行,而不是在最终处理的资产上进行。
CompressedImageSaver #

Bevy 0.12 附带了一个简单的 CompressedImageSaver,它将图像写入 Basis Universal(一种 GPU 友好的图像交换格式)并生成 mipmaps。Mipmaps 在从不同距离采样图像时减少混叠伪像。这填补了一个重要的空白,因为 Bevy 以前没有办法自己生成 mipmaps(它依赖于外部工具)。这可以通过 basis-universal Cargo 特性启用。
预处理是可选的! #
尽管最终(在未来的 Bevy 版本中)建议大多数人启用资产处理,但我们也承认 Bevy 在各种应用程序中使用。资产处理会引入额外的复杂性和工作流更改,有些人可能不想要!
这就是 Bevy 提供两种资产模式的原因
AssetMode::Unprocessed: 资产将直接从资产源文件夹(默认为assets)加载,无需任何预处理。假设它们处于其“最终格式”。这是 Bevy 用户目前习惯的模式/工作流程。AssetMode::Processed: 资产将在开发时预处理。它们将从其源文件夹(默认为assets)读取,然后写入其目标文件夹(默认为imported_assets)。
为了实现这一点,Bevy 对资产使用了一种新颖的方法:处理后的资产和未处理的资产之间的区别是视角。它们都使用相同的 .meta 格式,并且使用相同的 AssetLoader 接口。
可以使用任意逻辑定义 Process 实现,但我们强烈建议使用 LoadAndSave Process 实现。 LoadAndSave 接收任何 AssetLoader 并将结果传递给 AssetSaver。
这意味着如果您已经拥有 ImageLoader(加载图像),您只需要编写一些 ImageSaver 来以某种优化格式写入图像。这既节省了开发工作,又简化了支持处理和未处理场景。
构建为在任何地方运行 #
与游戏开发领域中的许多其他资产处理器不同,Bevy Asset V2 的 AssetProcessor 故意设计为在任何平台上运行。它不使用平台限制的数据库,也不需要运行网络服务器的能力/权限。它可以与发布的应用程序一起部署,如果您的应用程序逻辑需要在运行时处理。
一个值得注意的例外:我们仍然需要进行一些更改才能使其在 Web 上运行,但它是考虑到 Web 支持而构建的。
递归资产依赖项加载事件 #
AssetEvent 枚举现在有一个 AssetEvent::LoadedWithDependencies 变体。当 Asset、其依赖项以及所有后代/递归依赖项都已加载时,会发出此事件。
这使得在执行某些操作之前,很容易等待 Asset“完全加载”。
多个资产源 #
现在可以注册多个 AssetSource(它取代了旧的单片“资产提供者”系统)。
从“默认” AssetSource 加载与以前 Bevy 版本中的加载方式完全相同
sprite.texture = assets.load;
但在 Bevy 0.12 中,您现在可以注册命名的 AssetSource 条目。例如,您可以注册一个 remote AssetSource,它从 HTTP 服务器加载资产
sprite.texture = assets.load;
热重载、元文件和资产处理等功能在所有源中都受支持。
您可以像这样注册一个新的 AssetSource
// reads assets from the "other" folder, rather than the default "assets" folder
app.register_asset_source
)
嵌入式资产 #
推动 多个资产源 的一项功能是改进我们的“嵌入二进制文件”资产加载。旧的 load_internal_asset! 方法存在许多问题(请参阅 此 PR 中的相关部分)。
旧的系统如下所示
pub const MESH_SHADER_HANDLE: = weak_from_u128;
load_internal_asset!;
这需要很多样板代码,并且没有与资产系统的其余部分无缝集成。 AssetServer 不了解这些资产,热重载需要一个特殊情况下处理的第二个 AssetServer,并且您无法使用 AssetLoader 加载资产(它们必须在内存中构造)。不是很好!
为了验证 多个资产源 的实现,我们构建了一个新的 embedded AssetSource,它用自然适合资产系统的东西取代了旧的 load_internal_asset! 系统
// Called in `crates/bevy_pbr/src/render/mesh.rs`
embedded_asset!;
// later in the app
let shader: = asset_server.load;
这比旧方法的样板代码少了很多!
由于 embedded 源与任何其他资产源一样,因此它可以干净地支持热重载...与旧系统不同。要热重载嵌入在二进制文件中的资产(例如:要获取嵌入在二进制文件中的着色器上的实时更新),只需启用新的 embedded_watcher Cargo 特性即可。
好多了!
可扩展的 #
Bevy Asset V2 中几乎所有内容都可以通过特质实现进行扩展
Asset: 定义新的资产类型AssetReader: 定义自定义AssetSource读取逻辑AssetWriter: 定义自定义AssetSource写入逻辑AssetWatcher: 定义自定义AssetSource监控/热重载逻辑AssetLoader: 定义给定Asset类型的自定义加载逻辑AssetSaver: 定义给定Asset类型的自定义保存逻辑Process: 定义完全定制的处理器逻辑(或使用更具意见的LoadAndSaveProcess实现)
异步资产 I/O #
新的 AssetReader 和 AssetWriter API 是异步的!这意味着自然异步后端(如网络 API)可以直接在期货上调用 await。
文件系统实现(如 FileAssetReader)将文件 IO 卸载到一个单独的线程,并且当文件操作完成后期货解析。
改进的热重载工作流程 #
以前的 Bevy 版本需要在您的应用程序代码中手动启用资产热重载(除了启用 filesystem_watcher Cargo 特性)。
// Enabling hot reloading in old versions of Bevy
app.add_plugins
这不太理想,因为发布的应用程序版本通常不希望启用文件系统监视。
在 Bevy 0.12 中,我们通过使新的 file_watcher Cargo 特性默认在您的应用程序中启用文件监视来改进此工作流程。在开发期间,只需使用启用了该特性的应用程序运行您的应用程序
在发布时,只需省略该特性即可。无需代码更改!
更好的资产句柄 #
资产句柄现在在其核心使用单个 Arc 来管理资产的生存期。这大大简化了内部机制,也使我们能够直接从句柄中获取更多资产信息。
值得注意的是,在 Bevy 0.12 中,我们使用它来提供直接从 Handle 访问 AssetPath。
// Previous version of Bevy
let path = asset_server.get_handle_path;
// Bevy 0.12
let path = handle.path;
句柄现在还在内部使用一个更小/更便宜的查找 AssetIndex,它使用代数索引在密集存储中查找资产。
真正的写时复制资产路径 #
AssetServer 和 AssetProcessor 在多个线程之间执行了大量的 AssetPath 克隆操作。在 Bevy 的早期版本中,AssetPath 是由 Rust 的 Cow 类型支持的。然而在 Rust 中,克隆一个 "拥有" 的 Cow 会导致内部值的克隆。这不是我们希望 AssetPath 的 "写时复制" 行为。我们在多个线程之间使用 AssetPath,因此我们 *需要* 从一个 "拥有" 的值开始。
为了防止所有这些字符串的克隆和重新分配,我们创建了自己的 CowArc 类型,AssetPath 在内部使用它。它有两个技巧。
- "拥有" 的变体是一个
Arc<str>,我们可以廉价地克隆它,而不会重新分配字符串。 - 几乎 *所有* 在代码中定义的
AssetPath值都来自一个&'static str。我们创建了一个特殊的CowArc::Static变体,它保留了这种静态性,这意味着即使将借用转换为 "拥有AssetPath",我们也 *不会* 执行任何分配。
Android 上的挂起和恢复 #
在 Android 上,应用程序不再在挂起时崩溃。相反,它们会暂停,并且在应用程序恢复之前,所有系统都不会运行。
这解决了 Android 应用程序的最后一个 "重大" 障碍!Bevy 现在支持 Android!
在其他线程中运行的后台任务(如播放音频)不会停止。当应用程序被挂起时,会发送一个 Lifetime 事件 ApplicationLifetime::Suspended,对应于 onStop() 回调。您应该注意暂停在后台不应该运行的任务,并在收到 ApplicationLifetime::Resumed 事件时恢复它们(对应于 onRestart() 回调)。
材质扩展 #
Bevy 拥有一个强大的着色器导入系统,允许模块化(和细粒度)的着色器代码复用。在 Bevy 的早期版本中,这意味着理论上,您可以导入 Bevy 的 PBR 着色器逻辑,并在您自己的着色器中使用它。然而在实践中,这很具有挑战性,因为您必须自己重新连接所有内容,这需要对基础材质有深入的了解。对于像 Bevy 的 PBR StandardMaterial 这样的复杂材质,这充满了样板代码,会导致代码重复,并且容易出错。
在 **Bevy 0.12** 中,我们构建了一个 **材质扩展** 系统,它能够定义建立在现有材质基础上的新材质。

这是通过新的 ExtendedMaterial 类型实现的。
app.add_plugin;
let material = ;
我们还将其与一些 StandardMaterial 着色器重构相结合,以便更轻松地选择您需要的部分。
// quantized_material.wgsl
@group @binding
my_extended_material: QuantizedMaterial;
@fragment
这 *极大地* 简化了编写自定义 PBR 材质的过程,使其几乎每个人都能使用!
绘图命令的自动批处理和实例化 #
**Bevy 0.12** 现在可以自动对绘图命令进行批处理/实例化,尽可能地减少绘图调用次数。这减少了绘图调用的数量,从而带来了显著的性能提升!
这需要进行一些架构更改,包括我们存储和访问每个实体的网格数据的方式(稍后会详细介绍)。
以下是一些关于旧的未批处理方法(0.11)和新的批处理方法(0.12)的基准测试结果。
2D 网格 Bevymark(每秒帧数,越高越好) #
它渲染了 160,000 个带有纹理的四边形网格实体(160 组,每组 1,000 个实体,每组共享一个材质)。这意味着我们可以对每组进行批处理,从而在启用批处理的情况下只产生 160 个实例化绘图调用。这使得 **帧速率提高了 200%(3 倍)**!

3D 网格 "多个立方体"(每秒帧数,越高越好) #
它渲染了 160,000 个立方体,其中约 11,700 个在视野中可见。这些立方体使用所有可见立方体的单个实例化绘图绘制,这使得 **帧速率提高了 100%(2 倍)**!

这些性能优势可以在所有平台上使用,包括 WebGL2!
哪些可以进行批处理? #
批处理/实例化只能针对不需要 "重新绑定" 的 GPU 数据进行操作(绑定是使数据可供着色器/管道使用,这会产生运行时成本)。这意味着如果像管道(着色器)、绑定组(着色器可访问的绑定数据)、顶点/索引缓冲区(网格)这样的内容不同,则无法进行批处理。
从总体上讲,目前具有相同材质和网格的实体可以进行批处理。
我们正在研究使更多数据在没有重新绑定的情况下可访问的方法,例如无绑定纹理、将网格合并到更大的缓冲区中等等。
选择退出 #
如果您希望从自动批处理中选择退出某个实体,可以向其添加新的 NoAutomaticBatching 组件。
这通常用于您正在执行自定义的、非标准的渲染器功能,这些功能与批处理的假设不兼容。例如,它假设视图绑定在所有绘图中都是恒定的,并且使用的是 Bevy 自建的实体批处理逻辑。
通往 GPU 驱动渲染的道路 #
Bevy 的渲染器性能对于 2D 和 3D 网格来说可以大幅提升。在 CPU 和 GPU 方面都存在瓶颈,可以减轻这些瓶颈,从而获得更高的帧速率。与 Bevy 的一贯做法一样,我们希望最大程度地利用您使用的平台,从 WebGL2 和移动设备的限制到高端的原生离散显卡。一个坚实的基础可以支持这一切。
在 **Bevy 0.12** 中,我们已经开始重新设计渲染数据结构、数据流和绘图模式,以解锁新的优化。这使我们能够在 **Bevy 0.12** 中实现 **自动批处理和实例化**,并且也有助于为未来其他重大改进(例如 GPU 驱动渲染)铺平道路。我们还没有准备好使用 GPU 驱动渲染,但我们在 **Bevy 0.12** 中已经迈出了这一步!
什么是 CPU 驱动渲染和 GPU 驱动渲染? #
CPU 驱动渲染是指在 CPU 上创建绘图命令。在 Bevy 中,这意味着 "在 Rust 代码中",更具体地说是在渲染图节点中。这是 Bevy 目前启动绘图的方式。
在 GPU 驱动渲染中,绘图命令由 GPU 上的 计算着色器 进行编码。这利用了 GPU 并行性,并解锁了更多高级的剔除优化,这些优化在 CPU 上难以实现,此外还有许多其他方法可以带来巨大的性能提升。
需要更改什么? #
从历史上看,Bevy 的通用 GPU 数据模式是为每个实体绑定每个数据块,并为每个实体发出一个绘图调用。在某些情况下,我们将数据存储在 "数组样式" 的统一缓冲区中,并使用动态偏移量进行访问,但这仍然会导致在每个偏移量处重新绑定。
所有这些重新绑定都会对 CPU 和 GPU 性能产生影响。在 CPU 上,这意味着编码绘图命令需要更多步骤进行处理,花费的时间比必要的时间更多。在 GPU(以及图形 API 中),这意味着更多的重新绑定和单独的绘图命令。
避免重新绑定既是 CPU 驱动渲染的重大性能优势,也是启用 GPU 驱动渲染的必要条件。
为了避免重新绑定,我们正在努力实现的通用数据模式是
- 对于每个数据类型(网格、材质、变换、纹理),创建一个包含所有该类型项的单个数组(或少量数组)。
- 将这些数组绑定少量次数(理想情况下只有一次),避免每个实体/每个绘图的重新绑定。
在 **Bevy 0.12** 中,我们已经认真地开始了这一过程!我们进行了一些架构更改,这些更改已经开始发挥作用。由于这些更改,我们现在可以 自动对具有完全相同网格和材质的实体进行批处理和实例化绘图。随着我们在这条道路上不断前进,我们可以对更多类型的场景进行批处理/实例化,从而减少越来越多的 CPU 工作量,直到最终实现 "完全 GPU 驱动"。
重新排序渲染集 #
对于某些实例化绘图方法,需要知道绘图的顺序,以便可以排列数据,并按顺序查找。例如,当每个实例数据存储在实例速率顶点缓冲区中时。
在 **Bevy 0.12** 之前的渲染集顺序会导致一些问题,因为在知道绘图顺序之前必须准备数据(写入 GPU)。当我们计划在 GPU 上拥有一个有序的实体数据列表时,这不是理想的选择。以前的集合顺序是

这在许多当前(和计划的)渲染器功能中造成了摩擦(和次优实例化)。最值得注意的是,在 Bevy 的早期版本中,它会导致精灵批处理出现这些问题。
0.12 中新的渲染集顺序是

引入 PrepareAssets 是因为我们只想在资产准备就绪的情况下将实体排队进行绘制。每帧的数据准备仍然发生在 Prepare 集合中,特别是在其 PrepareResources 子集中。它现在位于 Queue 和 Sort 之后,因此知道绘图顺序。这对于批处理也更有意义,因为它现在在批处理时知道是否需要绘制渲染阶段中另一种类型的实体。绑定组现在有一个明确的子集,它们应该在其中创建... PrepareBindGroups。
BatchedUniformBuffer 和 GpuArrayBuffer #
好的,因此我们需要以一种可以尽可能少地绑定它们并从它们绘制多个实例的方式,将许多相同类型的数据块放入缓冲区中。我们如何做到这一点呢?
在 Bevy 的早期版本中,每个实例的 MeshUniform 数据存储在统一缓冲区中,每个实例的数据与动态偏移量对齐。在绘制每个网格实体时,我们会更新动态偏移量,这在成本上可能与重新绑定相近。它看起来像这样

实例速率顶点缓冲区是一种方法,但它们对特定顺序非常有限。它们可能适合于网格实体变换之类的每个实例数据,但不能用于材质数据。其他主要选择是统一缓冲区、存储缓冲区和数据纹理。
WebGL2 不支持存储缓冲区,只支持统一缓冲区。在 WebGL2 中,每个绑定处的统一缓冲区的最小保证大小为 16kB。存储缓冲区(如果可用)的最小保证大小为 128MB。
数据纹理对于结构化数据来说要笨拙得多。而且在不支持线性数据布局的平台上,它们的性能会更差。
鉴于这些约束,我们希望在支持存储缓冲区的平台上使用存储缓冲区,而在不支持存储缓冲区的平台上(例如 WebGL 2)使用统一缓冲区。
批量统一缓冲区 #
对于统一缓冲区,我们必须假设在 WebGL2 上我们一次可能只能访问 16kB 的数据。举个例子,MeshUniform 每个实例需要 144 字节,这意味着我们可以在每个 16kB 绑定中拥有 113 个实例的批次。如果我们想总共绘制超过 113 个实体,我们需要一种方法来管理可以按每个实例批次的动态偏移量绑定的统一缓冲区数据。这就是 BatchedUniformBuffer 的设计目的。
BatchedUniformBuffer 看起来像这样

注意实例数据如何可以更紧密地打包,在更小的空间内容纳相同数量的已用数据。此外,我们只需要为每个批次更新绑定的动态偏移量。
GpuArrayBuffer #
鉴于我们需要为给定数据类型支持统一和存储缓冲区,这增加了实现新的底层渲染器功能所需的复杂性水平(在 Rust 代码和着色器中)。面对这种复杂性,一些开发人员可能会选择只使用存储缓冲区(实际上放弃了对 WebGL 2 的支持)。
为了尽可能轻松地支持两种存储类型,我们开发了 GpuArrayBuffer。这是一个 T 值的通用集合,抽象了 BatchedUniformBuffer 和 StorageBuffer。它将为当前平台/GPU 使用正确的存储。
StorageBuffer 中的数据看起来像这样

所有实例数据都可以直接一个接一个地放置,我们只需要绑定一次。不需要任何动态偏移量绑定,因此不需要任何对齐填充。
查看此带注释的代码示例,它说明了使用 GpuArrayBuffer 来支持统一和存储缓冲区绑定。
使用 GpuArrayBuffer 的 2D/3D 网格实体 #
2D 和 3D 网格实体渲染已迁移到使用 GpuArrayBuffer 来处理网格统一数据。
仅仅避免重新绑定网格统一数据缓冲区就能使帧速率提高约 6%!
实体哈希映射渲染器优化 #
从 Bevy 0.6 开始,Bevy 的渲染器已将数据从“主世界”提取到一个单独的“渲染世界”。这使得 流水线渲染 成为可能,它在渲染应用程序中渲染帧 N,而主应用程序模拟帧 N+1。
设计的一部分包括在帧之间清除渲染世界中的所有实体。这使得在主世界和渲染世界之间能够进行一致的实体映射,同时仍然能够在渲染世界中生成在主世界中不存在的新实体。
不幸的是,这种 ECS 使用模式也带来了一些严重的性能问题。为了获得良好的“线性迭代读取性能”,我们希望使用“表格存储”(Bevy 的默认 ECS 存储模型)。但是,在渲染器中,实体在每一帧都会被清除和重新生成,组件被插入到许多系统和渲染应用程序调度中的不同部分。这导致了许多“原型移动”,因为从各种渲染器上下文插入了新组件。当实体移动到新的原型时,它的所有“表格存储”组件都会被复制到新原型的表格中。在许多原型移动和/或大型表格移动中,这可能会很昂贵。
不幸的是,这在很大程度上浪费了性能。长期以来,我们讨论了许多关于如何改进它的想法。
前进的道路 #
主要的两种前进道路是
- 跨帧持久化渲染世界实体及其组件数据
- 停止使用实体表格存储来存储渲染世界中的组件数据
我们决定探索选项 (2) 作为 Bevy 0.12,因为持久化实体涉及解决其他没有简单且令人满意的答案的问题(例如:我们如何使世界完全同步而不会泄漏数据)。我们最终可能会找到这些答案,但现在我们选择了阻力最小的道路!
我们最终使用的是 HashMap<Entity, T>,它使用由 @SkiFire13 设计的优化哈希函数,并受到 rustc-hash 的启发。它以 EntityHashMap 的形式公开,是存储渲染世界中组件数据的新方式。
这 带来了显著的性能提升。
使用 #
使用它的最简单方法是使用新的 ExtractInstancesPlugin。它将提取匹配查询的所有实体,或者仅提取可见的那些实体,将多个组件一次提取到一个目标类型中。
将要一起访问的组件数据分组到一个目标类型中是一个好主意,以避免进行多次查找。
要从可见实体提取两个组件
app.add_plugins;
精灵实例化 #
在以前版本的 Bevy 中,精灵是通过生成一个顶点缓冲区来渲染的,该缓冲区包含每个精灵 4 个顶点,其中包含位置、UV 和可能的颜色数据。这已被证明非常有效。但是,由于使用不同的颜色而必须将精灵批次拆分为多个绘制,这是不太理想的。
精灵渲染现在使用实例级顶点缓冲区来存储每个实例数据。实例级顶点缓冲区在实例索引更改时而不是在顶点索引更改时步进。新缓冲区包含一个仿射变换矩阵,它可以在一个变换中实现平移、缩放和旋转。它包含每个实例的颜色以及 UV 偏移量和缩放比例。
这保留了以前方法的所有功能,能够实现任何精灵能够具有颜色色调并且仍然能够在同一个批次中绘制的额外灵活性,并且每个精灵使用 80 字节,而以前是 144 字节。
这导致了性能提高了高达 40%,比以前的方法快!
Rust 风格的着色器导入 #
Bevy 着色器现在使用 Rust 风格的着色器导入
// old
#import forward_io VertexOutput
// new
#import VertexOutput
与 Rust 导入一样,您可以使用大括号来导入多个项目。现在也支持多级嵌套!
// old
#import pbr_functions alpha_discard, apply_pbr_lighting
#import bevy_pbr mesh_bindings
// new
#import
与 Rust 模块一样,您现在可以导入部分路径
#import path
// later in the shader
function;
您现在也可以使用完全限定路径,而无需导入
pbr
Rust 风格的导入消除了旧系统中的许多“API 怪异”陷阱,并扩展了导入系统的功能。通过重用 Rust 语法和语义,我们消除了 Bevy 用户学习新系统的必要性。
glTF 发射强度 #
Bevy 现在在加载 glTF 资产时读取并使用 KHR_materials_emissive_strength glTF 材质扩展。这在从 Blender 等程序导入 glTF 时添加了对发射材质的支持。这些立方体中的每一个都有越来越高的发射强度

在 glTF 文件中导入第二个 UV 贴图 #
Bevy 0.12 现在如果在 glTF 文件中定义了第二个 UV 贴图 (TEXCOORD1 或 UV1),则会导入它并将其公开给着色器。通常,这常用于光照贴图 UV。这是一个经常被要求的功能,它解锁了光照贴图场景(在自定义用户着色器和未来的 Bevy 版本中)。
线框改进 #
线框现在使用 Bevy 的 Material 抽象。这意味着它将自动使用新的批处理和实例化功能,同时易于维护。此更改还使添加对彩色线框的支持变得更加容易。您可以使用 WireframeColor 组件全局或按网格配置颜色。现在也可以通过使用 NoWireframe 组件禁用线框渲染。

外部渲染器上下文 #
从历史上看,Bevy 的 RenderPlugin 始终负责初始化 wgpu 渲染上下文。但是,一些第三方 Bevy 插件,例如正在开发中的 bevy_openxr 插件,需要对渲染器初始化进行更多控制。
因此,在 Bevy 0.12 中,我们已经允许在启动时传入 wgpu 渲染上下文。这意味着第三方 bevy_openxr 插件可以成为一个“普通”的 Bevy 插件,而无需分叉 Bevy!
这是一个 Bevy VR 的简短视频,由 bevy_openxr 提供!
绑定组人体工程学 #
在为底层渲染器功能定义“绑定组”时,我们使用以下 API
render_device.create_bind_group;
这工作得相当好,但对于大量的绑定组来说,BindGroupEntry 样板代码使读取和写入所有内容(以及保持索引更新)变得比必要时更困难。
Bevy 0.12 添加了其他选项
// Sets the indices automatically using the index of the tuple item
render_device.create_bind_group;
// Manually sets the indices, but without the BindGroupEntry boilerplate!
render_device.create_bind_group;
一次性系统 #
通常,系统每帧运行一次,作为调度的一部分。但这并不总是合适的。也许您正在响应非常罕见的事件,例如在复杂回合制游戏中,或者只是不想用每个按钮的单独系统来塞满您的调度。一次性系统颠覆了这种逻辑,并为您提供了按需运行任意逻辑的能力,使用强大的、熟悉的系统语法。
;
使用一次性系统有三个简单的步骤:注册一个系统,存储其 SystemId,然后使用独占世界访问或命令来运行相应的系统。
仅仅通过这些,就能实现很多功能,然而SystemIds 的真正力量在于将其封装到组件中。
use SystemId;
;
// calling all callbacks!
然后,可以将一次性系统附加到 UI 元素上,例如按钮、RPG 中的动作,或任何其他实体。你甚至可能受到启发,使用一次性系统和 aery 来实现 Bevy 调度图(顺便说一下,请告诉我们结果如何)。
一次性系统非常灵活。它们可以嵌套,因此你可以在一次性系统中调用run_system。可以同时注册一个系统的多个实例,每个实例都有自己的Local 变量和缓存的系统状态。它也能很好地与基于资产的工作流配合使用:在序列化回调中记录从字符串到标识符的映射比尝试使用 Rust 函数这样做要好得多!
然而,一次性系统并非没有限制。目前,无法使用专有系统和为系统管道设计的系统(使用In 参数或返回类型)。你也不允许从自身调用一次性系统,递归不可行。最后,一次性系统总是按顺序评估,而不是并行评估。虽然这降低了复杂性和开销,但对于某些工作负载,这可能比使用带有并行执行器的调度程序要慢得多。
但是,当你只是进行原型设计或编写单元测试时,这可能很麻烦:两个完整的函数和一些奇怪的标识符?对于这些情况,可以使用World::run_system_once 方法。
use RunSystemOnce;
;
let mut world = new;
world.;
world.run_system_once; // prints 1
world.run_system_once; // prints 2
这非常适合单元测试系统和查询,并且开销更低,使用更简单。但是,有一点需要注意。有些系统具有状态,无论是Local 参数、变更检测还是EventReader。这种状态不会保存在两次run_system_once 调用之间,从而导致奇怪的行为。Locals 在每次运行时都会重置,而变更检测将始终检测数据是否已添加/更改。小心点,你就会没事的。
system.map #
Bevy 0.12 添加了一个新的 system.map() 函数,它是 system.pipe() 的更便宜、更符合人体工程学的替代方案。
与 system.pipe() 不同,system.map() 仅接受一个普通的闭包(而不是另一个系统),该闭包接受系统的输出作为其参数。
app.add_systems;
// An adapter that logs errors
Bevy 提供了内置的error、warn、debug 和info 适配器,可以与 system.map() 一起使用,以便在每个级别记录错误。
简化并行迭代方法 #
Bevy 0.12 使并行 Query 迭代器 for_each() 与可变查询和不可变查询兼容,减少了 API 表面,无需再写两次mut。
// Before:
query.par_iter_mut.for_each_mut;
// After:
query.par_iter_mut.for_each;
通过 EntityMut 实现不相交的可变世界访问 #
Bevy 0.12 支持同时安全地访问多个 EntityMut 值,这意味着你可以同时修改多个实体(并访问所有组件)。
let = world.many_entities_mut;
*entity1..unwrap = *entity2..unwrap;
这也适用于查询。
// This would not have been expressible in previous Bevy versions
// Now it is totally valid!
你现在可以可变地迭代所有实体并访问其中的任意组件。
for mut entity in world.iter_entities_mut
这需要将 EntityMut 的访问范围缩减到仅其访问的实体(以前它有允许直接访问 World 的逃生舱)。使用 EntityWorldMut 获取旧的“全局访问”方法的等效方法。
统一的 configure_sets API #
Bevy 0.11 中引入的 Bevy 的 Schedule-First API 将大多数 ECS 调度程序 API 表面统一到一个单独的add_systems API 下。但是,我们没有为configure_sets 做一个统一的 API,这意味着存在两个不同的 API。
app.configure_set;
app.configure_sets在 Bevy 0.12 中,我们将这些统一到一个 API 下,以与我们在其他地方使用的模式保持一致,并减少不必要的 API 表面。
app.configure_sets;
app.configure_setsUI 材质 #
得益于新的 UiMaterial,Bevy 的材质系统已被引入 Bevy UI。

这个“圆形”UI 节点是用自定义着色器绘制的。
#import UiVertexOutput
@group @binding
input: CircleMaterial;
@fragment
@location
就像其他 Bevy 材质类型一样,它在代码中很容易设置!
// Register the material plugin in your App
app.add_plugins
// Later in your app, spawn the UI node with your material!
commands.spawn;
UI 节点轮廓 #
Bevy 的 UI 节点现在通过新的 Outline 组件支持在 UI 节点的“边界之外”绘制轮廓。 Outline 在布局中不占用任何空间。这与 Style::border 不同,后者在布局中“作为”节点的一部分存在。

commands.spawn
统一的Time #
Bevy 0.12 为 FixedUpdate 带来了两项重大的生活质量改进。
Time现在为在FixedUpdate中运行的系统返回上下文相关的正确值。(因此,FixedTime已被移除。)FixedUpdate现在不再会陷入“死亡螺旋”(应用程序冻结,因为FixedUpdate步长被排队的速度快于它可以运行的速度)。
Bevy 0.10 中引入了 FixedUpdate 调度程序及其配套的FixedTime 资源,很快人们就发现FixedTime 有所欠缺。它的方法与 Time 不同,它甚至没有像 Time 那样跟踪“总共经过的时间”,仅举几个例子。拥有两个不同的“时间”API 也意味着你必须编写专门支持“固定时间步长”或“可变时间步长”的系统,而不是两者都支持。不进行这种划分是可取的,因为它会导致插件之间出现不兼容性(这在其他游戏引擎的插件中有时会出现)。
现在,你可以编写只读取 Time 并将其安排在任何上下文中运行的系统。
// This system will see a constant delta time if scheduled in `FixedUpdate` or
// a variable delta time if scheduled in `Update`.
大多数系统应该继续使用 Time,但在幕后,先前 API 中的方法已被重构为四个时钟。
Time<Real>Time<Virtual>Time<Fixed>Time<()>
Time<Real> 测量真正的、未经编辑的帧和应用程序持续时间。对于诊断/分析,使用该时钟。它也用于推导出其他时钟。Time<Virtual> 可以加速、减速和暂停,而Time<Fixed> 以固定增量追逐Time<Virtual>。最后,Time<()> 在进入或退出FixedUpdate 时会自动用Time<Fixed> 或Time<Virtual> 的当前值覆盖。当系统借用Time 时,它实际上借用的是Time<()>。
尝试新的 时间示例 以更好地了解这些资源。
解决加速问题的办法是限制Time<Virtual> 从单个帧中可以推进多少。这样就限制了下一帧可以为 FixedUpdate 排队的次数,因此诸如帧延迟或计算机从长时间休眠中唤醒之类的事件不再会导致死亡螺旋。因此现在,应用程序不会冻结,但发生在 FixedUpdate 中的事情会显得慢下来,因为它将以暂时降低的速度运行。
ImageLoader 设置 #
为了利用 Bevy Asset V2 中新的 AssetLoader 设置,我们在 ImageLoader 中添加了 ImageLoaderSettings。
这意味着你现在可以按图像配置采样器、SRGB 属性和格式。这些是默认值,如 Bevy Asset V2 元数据文件中所示。
当设置为Default 时,图像将使用 ImagePlugin::default_sampler 中配置的任何内容。
但是,你可以将这些值设置为你想要的任何值!
GamepadButtonInput #
Bevy 通常提供两种处理给定类型输入的方法。
- 事件:按顺序接收输入事件流。
Input资源:读取输入的当前状态。
一个值得注意的例外是 GamepadButton,它只能通过 Input 资源获得。Bevy 0.12 添加了一个新的 GamepadButtonInput 事件,填补了这一空白。
SceneInstanceReady 事件 #
Bevy 0.12 添加了一个新的 SceneInstanceReady 事件,使监听特定场景实例是否准备就绪变得很容易。“准备就绪”在此处意味着“已完全作为实体生成”。
;
拆分计算出的可见性 #
ComputedVisibility 组件现已拆分为 InheritedVisibility(在层次结构中可见)和 ViewVisibility(从视图中可见),使得能够分别对这两组数据使用 Bevy 的内置变更检测。
ReflectBundle #
Bevy 现在通过 ReflectBundle 支持“Bundle 反射”。
这使得可以使用 Bevy Reflect 创建和交互 ECS 捆绑包,这意味着你可以在运行时动态执行这些操作。这对于脚本和资产场景很有用。
反射命令 #
现在可以使用 Commands 上的新函数在普通系统中将反射组件插入到实体中并从实体中移除反射组件!
;
上面的命令默认使用 AppTypeRegistry。如果你使用不同的 TypeRegistry,则可以使用...with_registry 命令代替。
有关更多示例和文档,请参阅 ReflectCommandExt。
限制后台 FPS #
如果一个应用程序没有窗口处于焦点状态,Bevy 现在将限制其更新速率(默认情况下为 60Hz)。
之前,许多在桌面操作系统(尤其是 macOS)上运行的 Bevy 应用程序在窗口最小化或完全被覆盖时,即使启用了 VSync,也会出现 CPU 使用率激增的情况。造成这种情况的原因是,许多桌面窗口管理器会忽略对不可见窗口的 VSync。由于 VSync 通常会限制应用程序更新的频率,因此在 VSync 实际上被禁用时,该速度限制就会消失。
现在,在后台运行的应用程序将在更新之间休眠以限制其 FPS。
唯一需要注意的是,大多数操作系统不会报告窗口是否可见,只会报告它是否处于焦点状态。因此,节流是基于焦点,而不是可见性。然后选择 60Hz 作为默认值,以在窗口未处于焦点状态但仍可见的情况下保持高 FPS。
AnimationPlayer API 改进 #
AnimationPlayer 现在具有用于控制播放的新方法,以及用于检查动画是否正在播放或已完成以及获取其 AnimationClip 句柄的实用程序。
set_elapsed 已被删除,取而代之的是 seek_to。elapsed 现在返回实际的经过时间,不受动画速度的影响。stop_repeating 已被删除,取而代之的是 set_repeat(RepeatAnimation::Never)。
let mut player = q_animation_player.single_mut;
// Check if an animation is complete.
if player.is_finished
// Get a handle to the playing AnimationClip.
let clip_handle = player.animation_clip;
// Seek to 1s in the current clip.
player.seek_to;
忽略模棱两可的组件和资源 #
模糊报告是 Bevy 调度程序的一个可选功能。启用时,它会报告修改相同数据但彼此之间没有排序的系统之间的冲突。虽然一些报告的冲突会导致细微的错误,但许多不会。Bevy 有几种现有的方法和两种新的方法可以忽略这些冲突。
现有的 API:ambiguous_with,它忽略特定集之间的冲突,以及 ambiguous_with_all,它忽略与其应用的集发生的所有冲突。此外,现在还有 2 个新的 API 允许你忽略特定类型数据的冲突,allow_ambiguous_component 和 allow_ambiguous_resource。这些会忽略世界中特定类型、组件或资源上系统之间的所有冲突。
;
// These systems are ambiguous on R
let mut app = new;
app.configure_schedules;
app.insert_resource;
app.add_systems;
app.;
// Running the app does not error.
app.update;
Bevy 现在使用此方法来忽略 Assets<T> 资源之间的冲突。大多数这些模糊都会修改不同的资产,因此无关紧要。
空间音频 API 人体工程学 #
一个简单的“立体声”(非 HRTF)空间音频实现是在最后一刻为 Bevy 0.10 英雄般地拼凑起来的,但实现有点简陋,而且不太用户友好。用户需要编写自己的系统来使用发射器和监听器位置更新音频接收器。
现在,用户只需将 TransformBundle 添加到其 AudioBundle 中,Bevy 就会处理剩下的事情!
commands.spawn;
音调音频源 #
现在可以通过音调播放音频,这对于调试音频问题、用作占位符或用于程序化音频非常有用。
Pitch 音频源可以从其频率和持续时间创建,然后用作 PitchBundle 中的源。
使用 正弦波 在给定频率下生成音频。通过同时播放多个音调音频源(如和弦或泛音),可以创建更复杂的声音。
在 Color 结构体中添加了 HSL 方法 #
你现在可以使用 h()、s()、l() 以及它们的 set_h()、set_s()、set_l() 和 with_h()、with_s()、with_l() 变体来操作 Color 结构体的色调、饱和度和亮度值,而无需克隆。以前你只能用 RGBA 值来做到这一点。
// Returns HSL component values
let color = ORANGE;
let hue = color.h;
// ...
// Changes the HSL component values
let mut color = PINK;
color.set_s;
// ...
// Modifies existing colors and returns them
let color = VIOLET.with_l;
// ...
减少了跟踪开销 #
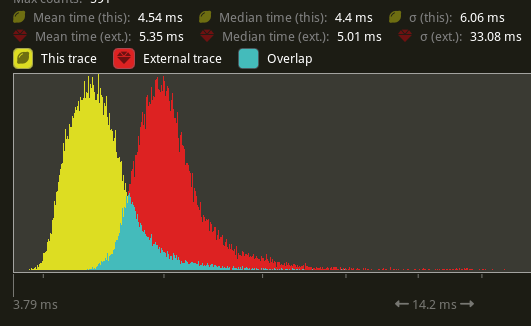
Bevy 使用 tracing 库来测量系统运行时间(以及其他一些事情)。这对于确定帧时间瓶颈所在并衡量性能改进非常有用。这些跟踪可以使用 tracy 工具可视化。但是,使用 tracing 的跨度会带来很大的开销。每个跨度的开销很大一部分是由于分配跨度的字符串描述。通过缓存系统、命令和并行迭代的跨度,我们显著地减少了使用 tracing 时的 CPU 时间开销。在引入系统跨度缓存的 PR 中,我们的“许多狐狸”压力测试从 5.35 毫秒降至 4.54 毫秒。在为并行迭代跨度添加缓存的 PR 中,我们的“许多立方体”压力测试从 8.89 毫秒降至 6.8 毫秒。
AccessKit 集成改进 #
Bevy 0.10 的 AccessKit 集成使得引擎可以非常轻松地率先推动对辅助功能树的更新。但正如任何优秀的舞蹈搭档都知道的那样,有时最好不要引导,而是要跟随。
此版本添加了 ManageAccessibilityUpdates 资源,该资源在设置为 false 时,会阻止引擎自行更新树。这为使用 Bevy 和 AccessKit 集成的第三方 UI 开辟了道路,以便直接向 Bevy 发送更新。当 UI 准备返回控制时,ManageAccessibilityUpdates 会被设置为 true,Bevy 会继续它之前的工作并开始再次发送更新。
AccessKit 本身也得到了简化,此版本利用了这一点来缩小我们集成的表面积。如果你对内部的工作原理感到好奇或想提供帮助,bevy_a11y crate 现在比以往任何时候都更容易接近。
TypePath 迁移 #
作为在 **Bevy 0.11** 中引入 稳定 TypePath 的后续行动,Bevy Reflect 现在使用 TypePath 而不是 type_name。反射类型现在可以通过 TypeInfo 和 DynamicTypePath 访问其 TypePath,并且已删除 type_name 方法。
改进的 bevymark 示例 #
bevymark 示例需要改进以能够对批处理/实例化绘制更改进行基准测试。添加了以下模式:
- 绘制 2D 四边形网格而不是精灵:
--mode mesh2d - 改变每个实例的颜色数据,而不仅仅是改变每波鸟类的颜色:
--vary-per-instance - 生成一定数量的材质/精灵纹理,并根据每个实例设置随机选择它们,无论是每波还是每个实例:
--material-texture-count 10 - 以随机 z 顺序(新默认值)或以绘制顺序生成鸟类:
--ordered-z
这允许对下一节中批处理/实例化的不同情况进行基准测试。
CI 改进 #
为了帮助确保示例在 Bevy 存储库之外可重用,CI 现在将如果示例使用来自 bevy_internal 而不是 bevy 的导入而失败。
此外,每日移动检查作业现在在更多 iOS 和 Android 设备上构建
- iPhone 13,iOS 15
- iPhone 14,iOS 16
- iPhone 15,iOS 17
- 小米 Redmi Note 11,Android 11
- Google Pixel 6,Android 12
- 三星 Galaxy S23,Android 13
- Google Pixel 8,Android 14
示例工具改进 #
示例展示工具现在可以为 WebGL2 或 WebGPU 构建所有示例。这用于使用所有与 Wasm 兼容的示例更新网站,你可以在 此处 找到 WebGL2 示例,或在 此处 找到 WebGPU 示例。
它现在还可以捕捉运行所有示例时的屏幕截图
有一些选项可以帮助执行,你可以使用 --help 检查它们。
这些屏幕截图显示在网站的示例页面上,可用于检查 PR 是否引入了可见的回归。
CI 中的示例执行 #
现在,所有示例都在 CI 中使用 DX12 在 Windows 上执行,使用 Vulkan 在 Linux 上执行。在可能的情况下,会拍摄屏幕截图并与上次执行的结果进行比较。如果示例崩溃,则会保存日志。移动示例也会在与每日移动检查作业相同的设备上执行。
所有这些执行的报告已生成,可在 此处 获取。
如果你想帮助赞助更多平台上的测试,请联系我们!
下一步? #
我们还有很多工作正在进行!其中一些可能会在 **Bevy 0.13** 中发布。
查看 Bevy 0.13 里程碑,以获取正在考虑用于 **Bevy 0.13** 的最新工作列表。
- Bevy 场景和 UI 演变:我们正在努力为 Bevy 打造新的场景和 UI 系统。我们正在尝试一种全新的 整体场景/UI 系统,希望它能成为 Bevy 编辑器的基础,并使在 Bevy 中定义场景更加灵活、强大和符合人体工程学。
- 更多批处理/实例化改进:将带骨骼的网格数据放入存储缓冲区,以便使用相同的网格/蒙皮/材质对带骨骼的网格实体进行实例化绘制。将材质数据放入新的 GpuArrayBuffer,以便对具有相同网格、材质类型和纹理但材质数据不同的实体进行批处理绘制。
- GPU 驱动渲染:我们计划通过在计算着色器中创建绘制调用(在支持该功能的平台上)来通过 GPU 驱动渲染。我们已经 使用网格体的实验,并将探索其他方法。这将涉及将纹理放入无绑定纹理数组,并将网格放入一个大型缓冲区以避免重新绑定。
- 曝光设置:控制 相机曝光设置 以改变渲染的风格和氛围!
- GPU 拾取:在 GPU 上 高效地选择对象,实现像素级精度!
- 每个对象的运动模糊:使用运动矢量 使移动的对象模糊
- UI 节点边框半径和阴影:在 Bevy UI 中支持 边框半径和阴影
- 系统步进:通过 逐步运行系统(针对特定帧)来调试你的应用程序
- 自动同步点: 支持在具有依赖关系的系统之间自动插入同步点,从而无需手动插入,并解决了一个常见的错误来源。
- 光照贴图支持: 支持渲染预烘焙的光照贴图
支持 Bevy #
赞助有助于使我们对 Bevy 的工作可持续。如果您相信 Bevy 的使命,请考虑赞助我们... 每一份帮助都至关重要!
贡献者 #
Bevy 由一个庞大的人群制作。非常感谢 185 位贡献者,他们使这个版本(以及相关的文档)成为可能!以随机顺序
- @miketwenty1
- @viridia
- @d-bucur
- @mamekoro
- @jpsikstus
- @johanhelsing
- @ChristopherBiscardi
- @GitGhillie
- @superdump
- @RCoder01
- @photex
- @geieredgar
- @cbournhonesque-sc
- @A-Walrus
- @Nilirad
- @nicoburns
- @hate
- @CrumbsTrace
- @SykikXO
- @DevinLeamy
- @jancespivo
- @ethereumdegen
- @Trashtalk217
- @pcwalton
- @maniwani
- @robtfm
- @stepancheg
- @kshitijaucharmal
- @killercup
- @ricky26
- @mockersf
- @mattdm
- @softmoth
- @tbillington
- @skindstrom
- @CGMossa
- @ickk
- @Aceeri
- @Vrixyz
- @Feilkin
- @flisky
- @IceSentry
- @maxheyer
- @MalekiRe
- @torsteingrindvik
- @djeedai
- @rparrett
- @SIGSTACKFAULT
- @Zeenobit
- @ycysdf
- @nickrart
- @louis-le-cam
- @mnmaita
- @basilefff
- @mdickopp
- @gardengim
- @ManevilleF
- @Wcubed
- @PortalRising
- @JoJoJet
- @rj00a
- @jnhyatt
- @ryand67
- @alexmadeathing
- @floppyhammer
- @Pixelstormer
- @ItsDoot
- @SludgePhD
- @cBournhonesque
- @fgrust
- @sebosp
- @ndarilek
- @coreh
- @Selene-Amanita
- @aleksa2808
- @IDEDARY
- @kamirr
- @EmiOnGit
- @wpederzoli
- @Shatur
- @ClayenKitten
- @regnarock
- @hesiod
- @raffaeleragni
- @floreal
- @robojeb
- @konsolas
- @nxsaken
- @ameknite
- @66OJ66
- @Unarmed
- @MarkusTheOrt
- @alice-i-cecile
- @arsmilitaris
- @horazont
- @Elabajaba
- @BrandonDyer64
- @jimmcnulty41
- @SecretPocketCat
- @hymm
- @tadeohepperle
- @Dot32IsCool
- @waywardmonkeys
- @bushrat011899
- @devil-ira
- @rdrpenguin04
- @s-puig
- @denshika
- @FlippinBerger
- @TimJentzsch
- @sadikkuzu
- @paul-hansen
- @Neo-Zhixing
- @SkiFire13
- @wackbyte
- @JMS55
- @rlidwka
- @urben1680
- @BeastLe9enD
- @rafalh
- @ickshonpe
- @bravely-beep
- @Kanabenki
- @tormeh
- @opstic
- @iiYese
- @525c1e21-bd67-4735-ac99-b4b0e5262290
- @nakedible
- @Cactus-man
- @MJohnson459
- @rodolphito
- @MrGVSV
- @cyqsimon
- @DGriffin91
- @danchia
- @NoahShomette
- @hmeine
- @Testare
- @nicopap
- @soqb
- @cevans-uk
- @papow65
- @ptxmac
- @suravshresth
- @james-j-obrien
- @MinerSebas
- @ottah
- @doonv
- @pascualex
- @CleanCut
- @yrns
- @Quicksticks-oss
- @HaNaK0
- @james7132
- @awtterpip
- @aevyrie
- @ShadowMitia
- @tguichaoua
- @okwilkins
- @Braymatter
- @Cptn-Sherman
- @jakobhellermann
- @SpecificProtagonist
- @jfaz1
- @tsujp
- @Serverator
- @lewiszlw
- @dmyyy
- @cart
- @teoxoy
- @StaffEngineer
- @MrGunflame
- @pablo-lua
- @100-TomatoJuice
- @OneFourth
- @anarelion
- @VitalyAnkh
- @st0rmbtw
- @fornwall
- @ZacHarroldC5
- @NiseVoid
- @Dworv
- @NiklasEi
- @arendjr
- @Malax
完整变更日志 #
A-ECS + A-Diagnostics #
A-ECS + A-Scenes #
A-Scenes #
- 将场景生成器系统移至 SpawnScene 调度程序
- 添加
SceneInstanceReady - 将
SpawnScene添加到 prelude - 完成
bevy_scene的文档记录 - 仅尝试从场景复制仍然存在的资源
- 更正场景加载器错误描述
A-Tasks + A-Diagnostics #
A-Tasks #
- 详细说明 TaskPool 和 bevy 任务
- 删除 Resource 并将 Debug 添加到 TaskPoolOptions
- 修复
single_threaded_task_pool中的 clippy 警告 - 删除
bevy_tasks的 README 中的依赖关系 - 允许在
bevy_tasks中使用async_io::block_on - 添加嵌套范围的测试
- 全局 TaskPool API 改进
A-Audio + A-Windowing #
A-Animation + A-Transform #
A-Transform #
A-App #
- 将
track_caller添加到App::add_plugins - 删除
ScheduleRunnerPlugin中对AppExit事件的冗余检查 - 修复
crates/bevy_app/src/app.rs中的拼写错误 - 修复
crates/bevy_app/src/app.rs中的拼写错误 - 修复一次性运行程序
A-ECS + A-App #
A-Rendering + A-Gizmos #
A-Rendering + A-Diagnostics #
A-Rendering + A-Reflection #
A-Windowing #
- 添加用于切换窗口控制按钮的选项
- 已修复:默认窗口现在是“App”,而不是“Bevy App”
- 改进与
WindowPlugin和Window相关的文档 - 改进
bevy_winit文档 - 将
WinitPlugin默认值更改为在窗口不可见时限制游戏更新速率 - 用户控制的窗口可见性
- 检查光标位置是否超出窗口范围
- 修复
transparent_window示例中的文档链接 - 在使窗口可见之前等待
- 不要在
winit StartCause::Init事件上创建窗口 - 修复
bevy_window的文档警告属性并记录剩余项目 - 恢复“macOS Sonoma (14.0) / Xcode 15.0 — 兼容性修复 + 文档…
- 恢复“macOS Sonoma (14.0) / Xcode 15.0 — 兼容性修复 + 文档…
- 允许 Bevy 从支持平台上的非主线程启动
- 防止启动期间出现黑屏
- 略微改进
CursorIcon文档。 - 修复
window.rs中的拼写错误
A-Gizmos #
- 用良好的序列替换 AHash,用于实体 AABB 颜色
- gizmo 插件滞后错误修复
- 在
Gizmos文档中阐明即时模式 - 修复使用少于 2 个顶点的绘制线形 gizmo 时发生的崩溃
- 记录 gizmo
depth_bias在 2D 中没有影响
A-Utils #
A-Rendering + A-Assets #
A-ECS #
- 将 Has world 查询添加到
bevy_ecs::prelude - 简化并行迭代方法
- 修复
WorldQuery::fetch的安全不变式并简化克隆 - 为 ManualEventIterator 派生调试
- 添加
EntityMap::clear - 在无生命周期模块文档中添加一段
- 选择退出
multi-threaded特性标志 - 修复
ambiguous_with中断运行条件 - 添加
RunSystem - 将
replace_if_neq添加到DetectChangesMut - 将
Copy, Clone, Debug添加到ExecutorKind的派生特征 - 修复
DetectChangesMut中的错误文档链接 - 实现
UnsafeWorldCell的Debug - 放宽
dyn System的In/Out边界对Debug的实现 - 改进各种
Debug实现 - 使
run_if_inner公开并将其重命名为run_if_dyn - 重构
build_schedule和相关的错误 - 添加
system.map(...)用于转换系统的输出 - 重新组织
Events和EventSequence代码 - 用 HashMap 替换 EntityMap
- 清理
configure_set(s)错误 - 在
Local上放宽更多Sync边界 - 重命名
ManualEventIterator - 替换
FnOnce的EntityCommand实现 - 添加
Events::update的一个变体,该变体返回已删除的事件 - 将调度程序名称移至
Schedule中 - 移植旧的歧义测试
- 将
EventReader::iter重构为read - 修复歧义报告
- 修复匿名集合名称栈溢出
- 修复
QueryState::is_empty中的不安全行为 - 添加用于从
Query获取组件的恐慌辅助函数 - 用
IntoSystemSetConfigs替换IntoSystemSetConfig - 将
get_component(_unchecked_mut)从Query移至QueryState - 修复“tick”列和 ComponentSparseSet 方法的命名
- 阐明
Option WorldQuery实现中的注释 - 从
set_if_neq返回一个布尔值 - 将
RemovedComponents::iter/iter_with_id重命名为read/read_with_id - 删除对 CoreSet 的一些旧引用
- 对原型基准测试使用单线程执行器
- docs:改进一些
ComponentId文档交叉链接。 - 一次性系统
- 在
filter_fetch上添加互斥安全信息 - 将
try_insert添加到实体命令 - 改进世界验证的代码生成
- docs:使用内部文档链接进行方法引用。
- 删除
States::variants并删除其派生的枚举限定 - 用于类似 Mut 的类型的
as_deref_mut()方法 - refactor:将
Option<With<T>>查询参数更改为Has<T> - 隐藏
UnsafeWorldCell::unsafe_world - 添加 ArchetypeGeneration/Id 的公共 API
- 忽略歧义组件或资源
- 在 breakout 示例中使用链
- 包含非发送参数的
ParamSet也应该是非发送的 - 用内部标签替换所有标签
- 修复引用 CoreSet 的过时注释
A-Rendering + A-Math #
A-UI #
- 修复垂直文本边界和对齐
- UI 提取顺序修复
- 使用默认字体更新文本示例
- bevy_ui:修复一些 Style 字段的文档格式
- 从
bevy_ui::render::extract_uinode_borders中删除With<Parent>查询过滤器 - 修复
ContentSize的 set 方法的错误文档注释 - 改进文本小部件文档注释
- 将
ContentSize的measure_func字段的默认值更改为 None。 game_menu示例中不必要的行- 将
UiScale更改为元组结构体 - 删除不必要的文档字符串
- 在 ui_node 中添加一些缺少的发布
- UI 示例清理
round_ties_up修复- 修复
JustifyItems和JustifySelf的错误文档 - 添加
Val::ZERO常量 - 清理一些 bevy_text pipeline.rs
- 使
GridPlacement的字段非零并添加访问器函数。 - 删除
Val的try_*算术方法 - UI 节点捆绑注释修复
- 对于 UI 实体的非 UI 子项,不要出现恐慌
- 将
Val的evaluate重命名为resolve并实现视口变体支持 - 将
Urect::width和Urect::height更改为常量 TextLayoutInfo::size应保存文本的绘制大小,而不是缩放后的值。- 对于
TextSection,impl From<String>和From<&str> - 在
extract_text2d_sprite中删除 z 轴缩放 - 修复对齐项的文档注释
- 向
bevy_ui::Layout添加测试 - 示例:删除未使用的文档注释。
- 从 impl 中添加缺少的
bevy_text特性属性到TextBundle - 将
Val移动到geometry中 - 为 UiRect 派生 Serialize 和 Deserialize
ContentSize替换修复- 在缩放后对 UI 坐标进行舍入
- 每个根节点都有一个单独的隐式视口节点 + 使视口节点为
Display::Grid - 将
num_font_atlases重命名为len。 - 修复 UI 节点样式的文档
text_wrap_debug缩放因子命令行参数- 在 Node 中存储圆形和未圆形的节点大小
- 各种辅助功能 API 更新。
- UI 节点轮廓
- 为一些 UI 类型实现序列化和反序列化
- 整理 UI 节点文档
- 当禁用 default_font 特性时,删除未使用的导入警告
- 修复某些右对齐文本的崩溃
- 为 bevy_text 添加更多文档。
- 为
Val实现Neg Rect的normalize方法- 不要为
Val实现Display - [bevy_text] 文档说明当未指定字体时会发生什么
- 更新 UI 对齐文档
- 向
Node添加堆栈索引 - 不要为
Val实现Display
A-Animation #
- 修复文档拼写错误
- 公开
animation_clip路径 - 动画:将蒙皮权重从 unorm8x4 转换为 float32x4
- AnimationPlayer 的 API 更新
- 只取不超过最大关节数
- 检查根节点的动画
- 修复变形插值
A-Pointers #
A-Assets + A-Reflection #
A-Rendering + A-Hierarchy #
A-ECS + A-Tasks #
A-Reflection + A-Utils #
A-Reflection + A-Math #
A-Hierarchy #
A-Input #
- 输入:允许在同一帧中为一个按钮注册多个游戏手柄输入
- Bevy 输入文档:lib.rs
- Bevy 输入文档:gamepad.rs
- 添加
GamepadButtonInput事件 - Bevy 输入文档:模块
- 完成
bevy_gilrs的文档 - 更改
AxisSettings活跃区默认值 - 文档:更新 input_toggle_active 示例
A-Input + A-Windowing #
A-ECS + A-Reflection #
- 实现插入和删除反射实体命令
- 允许通过
EntityMut进行不连续的可变世界访问 - 为
State<S>和NextState<S>实现Reflect #[derive(Clone)]在Component{Info,Descriptor}上
A-Math #
- 重命名 bevy_math::rects 转换方法
- 将 glam swizzles 特性添加到 prelude
- 为清晰起见,将
Bezier重命名为CubicBezier - 添加一种方法来计算包含一组点的边界框
- 重新导出
debug_glam_assert特性 - 在所有三次曲线生成器中添加
Cubic前缀
A-Build-System #
- 仅在依赖项树发生更改时检查禁令
- 贡献者修改示例模板时,消息略微更好
- 在 windows 和 linux 之间切换 CI 作业以执行示例
- 在 CI 中检查 bevy_internal 导入
- 修复在 CI 中在 linux 上运行示例
- 将 actions/checkout 从 2 提升到 4
- 文档:删除对
clippy::manual-strip的引用。 - 仅在 bevy 存储库(而不是分支)上运行一些工作流程
- 在更多设备/操作系统版本上运行移动测试
- 允许在更多地方使用
clippy::type_complexity。 - 在 github 运行器上的 CI 中运行(和截屏)示例的技巧
- 使 CI 在 cargo deny 禁令上减少失败
- 在 Android 14 / Pixel 8 上添加测试
- 更多地使用
clippy::doc_markdown。
A-Diagnostics #
A-Rendering + A-Animation #
A-Core #
A-Reflection #
- 修复 NamedTypePathDef 中的拼写错误
- 重构
bevy_reflect的path模块 - 重构 bevy_reflect 路径模块中的解析
- bevy_reflect:修复组合字段属性
- bevy_reflect:
TypePath的选择退出属性 - 添加 reflect 路径解析基准测试
- 使
ParsedPath可以传递到 GetPath - 使 reflect 路径解析器对 utf-8 不敏感
- bevy_scene:添加
ReflectBundle - 修复场景示例
FromResources中的注释 - 删除 TypeRegistry 重新导出重命名
- 为 ReflectFromPtr 的字段提供 getter
- 将 TypePath 添加到 prelude
- 改进 TypeUuid 的派生宏错误消息
- 将
Quat反射策略从“值”迁移到“结构体” - bevy_reflect:修复动态类型序列化
- bevy_reflect:修复忽略/跳过的字段顺序
A-Rendering + A-Assets + A-Reflection #
A-ECS + A-Time #
A-ECS + A-Hierarchy #
A-Audio #
A-Rendering + A-UI #
- 删除
Style::border中过时的段落 - 恢复“修复 AMD gpus 使用 Vulkan 时的 UI 损坏 (#9169)”
- 恢复“修复 AMD gpus 使用 Vulkan 时的 UI 损坏 (#9169)”
many_buttons增强功能- 修复 UI 边框
- UI 批处理修复
- 添加 UI 材质
A-ECS + A-Reflection + A-Pointers #
无区域标签 #
- 修复整个项目中的拼写错误
- 发布后提升版本
- 修复
clippy::default_constructed_unit_structs和 trybuild 错误 - 删除 0.11 中弃用的代码
- 在
prepare_uinodes中清空ExtractedUiNodes - 示例展示 - 分页和可以构建为 WebGL2
- 示例展示:将默认 API 切换到 webgpu
- 当 BevyManifest 找不到 Cargo.toml 时,添加一些更实用的错误
- 修复对贡献者示例的路径引用
- 将
Query文档中的括号替换为方括号以引用 _mut #9200 - 在压力测试中使用 AutoNoVsync
- bevy_render:删除对 wgpu-hal 的直接依赖。
- 修复第 322 行的拼写错误
- custom_material.vert:gl_InstanceIndex 包含 gl_BaseInstance
- 修复链接中的拼写错误 - 网格文档
- 改进与字体大小相关的文档
- 修复游戏手柄查看器被标记为非 wasm 示例
- Rustdoc:抓取示例
- 在基准测试中启用多线程
- webgl 特性重命名为 webgl2
- 示例注释拼写错误修复
- 修复 shader_instancing 示例
- 将 tracy-client 要求从 0.15 更新到 0.16
- 修复 bevy 导入。windows_settings.rs 示例
- 修复 Rust 1.72 的 CI
- 将 TransparentUi 切换为使用稳定排序
- 将
entity.insert的使用替换为game_menu示例中的元组捆绑 - 删除
&mut EventReader的IntoIterator实现 - 删除 VecSwizzles 导入
- 修复错误的 glam 版本
- 修复一些文档注释
- 明确使 instance_index 顶点输出 @interpolate(flat)
- 修复一些 nightly 警告
- 为 viewport_debug 示例使用默认分辨率
- 参考“macOS”,而不是“macOS X”。
- 删除无用的单个元组和尾随逗号
- 修复 nightly 中显示的一些警告
- 修复 text2d 示例中 animate_scale 对 z 值的缩放
- “serialize”特性不再启用可选的“bevy_scene”特性(如果它没有从其他地方启用)
- 修复基准测试中的弃用警告
- 在为 WebGPU 构建时不要启用 filesystem_watcher
- 改进文档格式。
- 修复
clippy::explicit_iter_looplint - Wslg 文档
- skybox.wgsl:修复精度问题
- 修复拼写错误。
- 在
TextBundle文档中添加指向Text2dBundle的链接。 - 修复一些拼写错误
- 修复拼写错误
- 将
parking_lot替换为std::sync - 向基准测试系统添加 inline(never)
- Android:处理挂起/恢复
- 修复 nightly 中显示的一些警告
- Rust 1.73 更新
- 改进移动示例中 iOS 设备的选择
- 将 toml_edit 要求从 0.19 更新到 0.20
- 狐狸不应该同步行进
- 修复色调映射测试图案
- 删除
once_cell - 改进 WebGPU 不稳定标志文档
- shadow_biases:支持不同的 PCF 方法
- shadow_biases:支持移动光源位置并重置偏差
- 将 async-io 要求从 1.13.0 更新到 2.0.0
- 一些 fmt 调整
- 为更多错误类型派生 Error
- 允许 AccessKit 在 WindowEvents 到达引擎之前对其做出反应
A-Rendering + A-Build-System #
A-Meta #
A-Assets + A-Animation #
A-Editor + A-Diagnostics #
A-Time #
- 修复 timers.rs 文档
- 在
bevy_time中添加缺失的文档 - 澄清
Timer::finished()对重复计时器的行为 - 忽略时间通道错误
- 统一
FixedTime和Time,同时修复了几个问题 - Time: 将 delta 时间钳制警告降级为调试级别
- 修复 time.rs 示例中的拼写错误
- 示例时间 API
A-Rendering + A-ECS #
A-UI + A-Reflection #
A-Build-System + A-Assets #
A-Rendering #
- 澄清 wgpu 基于 webGPU API
- 在 Camera::physical_viewport_rect 中返回 URect 而不是 (UVec2, UVec2)
- 修复 AssetPath 着色器的模块名称
- 添加 GpuArrayBuffer 和 BatchedUniformBuffer
- 更新
bevy_window::PresentMode以镜像wgpu::PresentMode - 停止在流水线渲染线程中使用 unwrap
- 修复加载 UASTC 编码的 ktx2 纹理时的恐慌
- 文档化
ClearColorConfig - 将 MeshUniform 用于 GpuArrayBuffer
- 更新 Orthographic 投影的 scaling_mode 字段的文档
- 在 #9254 之后修复 shader_material_glsl 示例
- 改进
Mesh文档 - 在 tonemapping_test_patterns 中包含 tone_mapping 函数
- 扩展 2D 相机的默认渲染范围
- 文档化 Camera::viewport_to_world 和相关方法何时返回 None
- 包含顶层与着色器相关的定义
- 修复 webgl2 上的 post_processing 示例
- 在 post_processing 示例中使用 ViewNodeRunner
- 解决 WebGL2 上 naga/wgpu WGSL instance_index -> GLSL gl_InstanceID 错误
- 修复着色器预处理示例中不可见的运动向量文本
- 使用 bevy 仓库的导入而不是 bevy 内部。post_processing 示例
- 制作锚点副本
- 将 window.rs 移动到 bevy_render 中的 window/mod.rs
- 减小 MeshUniform 的大小以提高性能
- 修复时间抖动错误
- 修复部分位于相机后面的 Gizmo 线形变或消失的问题
- 使 WgpuSettings::default() 检查 WGPU_POWER_PREF
- 修复 MeshUniform 大小减小后的线框
- 修复 shader_material_glsl 示例
- [彩虹效果] 添加从 Color 获取 HSL 分量的方法
- ktx2: 修复 Rgb8 -> Rgba8Unorm 转换
- 重新排序渲染集,重构 bevy_sprite 以利用优势
- 改进与
Frustum和HalfSpace相关的文档 - 还原“更新 OrthographicProjection 的默认值(#9537)”
- 从 bevy_render 中删除未使用的 regex 依赖项
- 将
ComputedVisibility拆分为两个组件,以允许准确的更改检测并加快可见性传播速度 - 对精灵使用实例化
- 增强 bevymark
- 删除 tonemapping 中冗余的数学运算。
- 改进
SpatialBundle文档 - 根据使用情况缓存深度纹理
- 对不同的顶点计数发出警告和最小值
- 将 16 位 rgb/rgba 纹理的默认值设置为 unorm 而不是 uint
- 修复 TextureAtlasBuilder 填充
- 添加
Camera::viewport_to_world的示例 - 修复带皮肤/变形网格的线框
- 为 Mikktspace 生成索引
- 反转对负缩放的 gltf 节点的面剔除
- 渲染器初始化: 仅在 wasm 上创建分离的任务,否则阻塞
- 清理
visibility模块 - 对大型绑定列表使用单行
- 修复
DirectionalLightBundle中的拼写错误 - 还原“更新 OrthographicProjection 的默认值(#9537)”
- 重构渲染系统以使用
let-else - 对 Transparent2d PhaseItem 排序使用 radsort
- 自动批处理/实例化绘制命令
- 直接将数据复制到统一缓冲区
- 允许其他插件创建渲染器资源
- 使用 EntityHashMap<Entity, T> 来存储渲染世界中的实体,以提高性能
- 并行化 extract_meshes
- 修复注释语法
- 允许覆盖全局线框设置。
- 线框: 为 DX12 解决问题
- 备用线框覆盖 API
- 修复 TextureAtlasBuilder 填充
- 修复示例 mesh2d_manual
- PCF 用于 DirectionalLight/SpotLight 阴影
- 重构 #9903 中的渲染实例逻辑,使其更易于其他组件采用。
- 修复 2d_shapes 和一般的 2D 网格实例化
- 修复 webgl2 崩溃
- 修复聚光灯剔除的正交集群 aabb
- 添加用于更符合人体工程学的
Mesh创建的消费构建器方法 - wgpu 0.17
- 对线框使用
Material - 在类型别名中提取通用的线框过滤器
- 延迟渲染器
- 可配置的线框颜色
- chore: 将 RenderInstance trait 重命名为 ExtractInstance
- pbr 着色器清理
- 修复 text2d 视图可见性
- 允许从主世界中可选地提取资源
- ssao 使用 unlit_color 而不是白色
- 修复 copy_deferred_lighting_id 名称中缺少显式生命周期名称
- 修复渲染中的 mod.rs 以支持 Radeon 显卡
- 解释
Materialtrait 的文档中预处理着色器的用法 - 为 prepare_windows 文档提供更好的链接
- 改进
RenderSet文档中的链接。 - 修复 unlit 缺失的参数
*_PREPASS着色器定义清理- 检查是否存在任何预处理阶段
- 允许对 StandardMaterial 进行扩展
- array_texture 示例: 使用 pbr 函数的新名称
- chore: 对 EnvironmentMapLight 和 FogSettings 使用 ExtractComponent 派生宏
- 变量
MeshPipeline视图绑定组布局 - 更新着色器导入
- 绑定组条目
- 检测 dds 纹理的立方体贴图
- 修复 ios 模拟器上的对齐问题
- 为 Image 添加便捷方法
- 使用“镜面遮挡”术语来一致地熄灭环境光和环境贴图灯光上的菲涅尔
- 修复雾色不准确的问题
- 将所有 texture_descritor.size.* 的用法替换为辅助方法
- 视图变换
- 修复延迟示例的雾值
- WebGL2: 修复 unpack_unorm3x4_plus_unorm_20_ 的导入路径
- 在 bevy_pbr 中使用通配符导入
- 使网格属性顶点计数不匹配警告更易读
- 图像采样器改进
- 修复使用非均匀控制流对漫反射环境贴图纹理进行采样
- 当
tonemapping_luts特性被禁用但所选调色器需要它时,记录一个警告。 - 较小的 TAA 修复
- 截断属性缓冲区数据而不是属性缓冲区
- 修复 WebGL2 中的 M1 上的延迟照明通道值并非全部工作
- 将视锥体添加到着色器视图
- 修复对法线贴图的
double_sided的处理 - 添加辅助函数以确定颜色是否透明
StandardMaterial光传输- 双面法线: 修复 apply_normal_mapping 调用
- 在 check_visibility_system 中合并可见性查询
- 使 VERTEX_COLORS 可用在预处理着色器中(如果可用)
- 允许 DeferredPrepass 在没有其他预处理标记的情况下工作
- 增加默认法线偏差以避免常见的伪影
- 使
DirectionalLight的Cascades计算对CameraProjection通用 - 更新默认
ClearColor以更好地匹配 Bevy 的品牌 - 修复预处理启用时 Gizmo 崩溃
A-Build-System + A-Meta #
A-Assets #
- doc(asset): 修复资产特性的示例
- 添加
GltfLoader::new。 - 对
HandleId实现From<&AssetPath> - 允许资产加载器预注册
- 修复对多个资产的资产加载器预注册
- 修复点光源半径
- 添加对 KHR_materials_emissive_strength 的支持
- 修复使用
.load_folder()和绝对路径时的恐慌 - Bevy Asset V2
- 如果需要,创建导入的资产目录
- 复制写入 AssetPaths
- Asset v2: 资产路径序列化修复
- 不要忽略一些 EventKind::Modify
- 手动“反射值”AssetPath 实现以修复动态链接
- 修复简单的 AssetV2 派生中的未使用的变量警告
- 删除 monkey.gltf
- 将 notify-debouncer-full 需求从 0.2.0 更新到 0.3.1
- 删除
anyhow - 多个资产源
- 使没有文件扩展名的加载警告更具描述性
- 修复非默认资产源的 load_folder
- 仅在资产插件未处理时设置处理过的源
- 热重载其源资产未加载的标记资产
- 加载不存在的标签时返回错误
- 删除 android 上未使用的导入
- 在构建 AssetPlugin 之后注册 AssetSource 时记录错误
- 添加有关资产源注册顺序的说明
- 添加
asset_processor特性并删除 AssetMode::ProcessedDev - 对 AssetPath 实现 source 到 Display
- assets: 使用 blake3 而不是 md5
- 减少资产处理示例中的噪声
- 添加 AssetPath::resolve() 方法。
- Assets: 修复第一次热重载
- 使用包装资产进行非阻塞 load_untyped
- 重用和热重载文件夹句柄
- 其他 AssetPath 单元测试。
- 更正 read_asset_bytes 上的错误文档注释
- 支持在单线程上下文中进行文件操作